Google, dont, rappelons-le, plus de 90 % du Chiffre d’Affaire trimestriel de 21 G$ (+18%) provient d’une forme ou d’une autre de publicité digitale, lance une grosse offensive pour inciter les entreprises à confier l’optimisation de leur publicité ciblée à des moteurs de machine learning (forme d’intelligence artificielle voir article http://bit.ly/2etAGjV) appelés “Programmatic Search”. En effet, les bonnes vieilles bannières affichées en fonction des mots-clés saisis par l’utilisateur et de son profil historique – ne sont plus aussi efficaces, et sont surtout, de plus en plus souvent, bloquées par les Adblocker.
Avant d’analyser davantage cette nouvelle et ses répercussions, faisons un retour en arrière sur ces dernières années pour bien comprendre les évolutions récentes dans la publicité digitale et la vente de profils, et découvrir ainsi des convergences transversales entre ce qui se passe dans la presse, l’IOT, et la maison connectée ou la musique :
- Fin 2009 : Facebook lance gratuitement pour les marques des murs sur lesquels elles peuvent faire leur promotion en animant une communauté de fans. Cela devient la course au nombre de fans pour les marques. Facebook va ensuite proposer aux marques de communiquer aux fans directement … en leur imposant un ciblage fait par Facebook, grâce son algorithme EDGERANK, car il est hors de question de bombarder de spams 100% des fans. C’est donc Facebook qui, connaissant le mieux les utilisateurs, qui sont en général fans de plusieurs marques, décide quels seront au début les 30% de fan qui recevront la publicité en question. Un taux qui a été réduit à 15 %, puis 5 %; et il y a deux ans : 0 %. Les marques se sont retrouvées complètement confuses car elles avaient oublié le paradigme numéro un : “uand c’est gratuit, c’est toi le produit”. Grâce à la complicité involontaire des marques, Facebook a pu développer, avec son outil de Like, une meilleure connaissance des utilisateurs, et ainsi revendre les profils enrichis à des boîtes spécialisées (Claritas, Datalogix, Acxiom), qui elles-mêmes revendent ces profils aux mêmes marques qui ont contribué gratuitement à constituer ces profils.
- Amazon, dont le propriétaire Jeff BEZOS a racheté à titre “personnel” le Washington Post, commence à faire des synergies entre les deux marques. Aux États-Unis, le Washington Post insère aujourd’hui par exemple, dans la livraison de l’article de pêche que vous venez de commander sur Amazon un article du Washington Post sur la pêche dans votre région. Ils ont donc des profils de plus en plus riches sur vos habitudes d’achat, de lecture (sur Washington Post et Kindle) et sur les vidéos pour les abonnés d’Amazon Prime …
- Google, grâce à vos Search, et de plus en plus grâce à vos vues sur YouTube, arrive également à avoir des profils très riches. Ils ont surtout compris comment tirer des revenus des vidéos les plus vues, en proposant à l’auteur de partager 50/50 les revenus provenant des publicités mises avant ou pendant le streaming. Principe que Google étend aux rédacteurs, blogueurs et journalistes avec le format AMP qui attache au document un manifeste donnant le droit d’utilisation signé par l’auteur. Google a aussi découvert après Deezer et Spotify, le business model de lasubscription economy proposé dans la musique qui doit être un nouveau business source de revenue à côté de la pub pour un auditoire voulant de la qualité musicale sans pub.
- Les agences, elles, se sont senties fortement menacées il y a deux ans par les anciens de Google qui allaient pantoufler chez les annonceurs, en étant mieux que quiconque grâce à leur connaissance de l’outil Adwords de Google. En fait, l’évolution des supports est tellement rapide et difficile à suivre que les agences sont toujours utiles pour aider les marques dans leur allocation des budgets publicité.
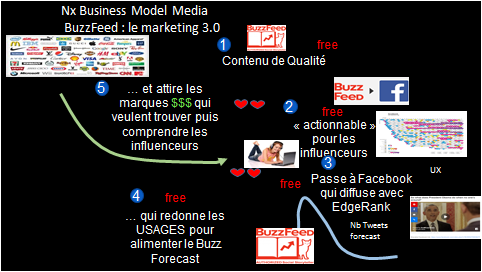
- Buzzfeed et Mashable, nouveaux médias créés il y a 12 ans, se concentrent sur lesinfluenceurs. Ils les aident à faire des articles pertinents en fonction de l’auditoire visé, en proposant un outil de Buzz forecasting capable d’extrapoler la durée de vie des buzz. Au SXSW en Mars 2015, ils expliquent leur changement important de business model (pivot) en mentionnant l’accord de diffusion qu’ils ont conclu avec Facebook, qui voulait mettre du contenu intéressant dans les fils d’actualités des utilisateurs. Ainsi, Buzzfeed et Mashable ont “donné” leurs articles à Facebook pour qu’ils soient diffusés dans les fils d’actualités Facebook, en échange uniquement de la User Experience (UX). En effet, la UX que Facebook offre aux créateurs de contenus est beaucoup plus riche que celle qu’ils avaient auparavant, sur Twitter par exemple, où ils voyaient uniquement tel message avait été retweeté. Facebook est capable de voir si vous avez partagé un article BuzzFeed avec votre conjoint, ou vos amis de bureau, ou votre équipe de foot … ce qui est très différent pour l’Influenceur qui vise une population précise. Fort de ce feed-back sur la UX, Buzzfeed est capable d’améliorer encore son outil Buzz-forecast qui fait sa notoriété. Et le business modèle de Buzzfeed dans tout ça ? Buzzfeed, comme une agence, va devenir un conseil auprès des marques qui veulent retrouver leurs influenceurs … pour essayer de les influencer.

- Dans le domaine de l’IOT (des objets connectés), les grands acteurs comme Google avec NEST, Amazon avec ECHO, ou encore Samsung, proposent une nouvelle approche dans laquelle l’information donnée par l’objet connecté est dissociée du service qu’il pourra rendre. En effet, pour rendre un bon service en matière de sécurité de la maison, il faut beaucoup d’informations sur vos habitudes de vie, au-delà de l’information venant des objets connectés dans votre domicile. Il propose donc depuis quelques mois une architecture dans laquelle l’objet connecté remonte l’information dans le Cloud, avec un manifeste qui précise le droit d’usage que Samsung se fait fort de faire respecter par toutes les sociétés de services qui auront accès à cette information. Par exemple, vous pourrez préciser que l’image provenant de la caméra vidéo dans votre salon ne pourra être utilisée qu’à des fins de sécurité, et non pas pour vous offrir votre liqueur préférée lorsque vous serez un peu déprimé. Ensuite, le service provider choisi par le client, par exemple BRINKS, pourra rassembler toutes les informations pour décider d’un service qui prendra par exemple la forme d’un ordre de fermer les volets. Samsung taxera le service provider par ordre envoyé.
Tous les acteurs ont compris que, pour faire face aux Adblock, ils devaient trouver une raison d’être légitime en tant que tiers de confiance, capable de faire la bonne suggestion au bon moment ce qui représenterait alors un service de qualité pour lequel le consommateur serait volontaire et donc prêt à ouvrir ses data perso si et seulement si il se sent “in control”. (Rappelons que ceux qui refusent ce monde de Big Data, dans lequel ils se trouvent manipulés comme des objets, peuvent inverser la proposition en passant d’une approche CRM à une approche VRM,où les informations personnelles ne quittent pas le serveur. Je partage éventuellement en “read only”, et pour un temps limité, les informations que je choisis avec ceux que je choisis).
Tous ces grands acteurs arrivent donc, grâce à ces profils enrichis, au Graal : être capable en tant que tiers de confiance de faire la bonne suggestion au bon moment à ses clients.Comme nous l’avons vu dans les différents business models, certains gardent ces informations jalousement pour eux comme Apple et, à moindre échelle, Amazon ; d’autres, comme Google ou Facebook, en font au contraire une activité très lucrative en revendant ces informations aux marques ou à des sociétés très spécialisées (Claritas, Datalogix, Acxiom…),qui elles-mêmes les revendent aux marques.
Et les marques, elles en font quoi de cette information riche et anonymisée ?
Elles les utilisent pour faire du Real Time Bidding (RTB) qui représente 50% des budgets publicitaires digitaux soit 25 % du total. Voir graphique The Economist.
![]()
Le RTB fonctionne de la façon suivante : Vous êtes en train de lire un article sur la cueillette des fraises sur le site de votre journal favoris, qui se trouve être le Washington Post. Le site, grâce aux cookies, vous a reconnu et est capable d’envoyer un profil anomymisé avec le maximum de vos caractéristiques pour que tous les annonceurs enchérissent et que, 100 M$ plus tard, la bannière la plus offrante se retrouve devant vos yeux.
C’est ainsi que, sur Madison Avenue, l’employé d’une agence de publicité qui gère le budget d’une marque et qui doit, par exemple, arriver à vendre des essais d’une nouvelle Mercedes, va miser pendant une demi-heure 1000 € pour acheter le plus de bannières sur un profil “55 ans, deux enfants et aimant le whisky”. 10 minutes ou une demi-heure plus tard, il a le résultat des 100 000 bannières achetées aux enchères en termes de taux de clics et de transformation, si son architecture est bien faite. Suivant ces résultats, il peut peaufiner immédiatement le tir en décidant la prochaine fois de miser sur “57 ans, un enfant et les vacances au soleil”.
Ce que propose Google avec « programmatic search » aujourd’hui, c’est de confier cette optimisation non plus à ce responsable d’agence sur Madison Avenue, mais à ses logiciels de machine learning (qui est une forme d’intelligence artificielle). D’après les premières estimations, les résultats sont nettement meilleurs, ce qui conduit les annonceurs, ou directement les agences qui travaillent pour eux, à dépenser plus d’argent sur ce ciblage très fin à partir de RTB automatiques.
En conclusion, un principe de base pour une nouvelle architecture des données pourrait être autour de ces manifestes, dans lequel le créateur de contenu spécifie ce qu’il est prêt à laisser faire avec ce contenu. Nous verrons comment progressent ces statistiques et si la solution d’une architecture avec “manifeste” fonctionne. Pour cela, il faudra que les gardiens de chaque cloud soient capables de :
- mettre en place une police efficace et transparente pour faire respecter l’engagement des manifestes par toutes les marques
- et surtout d’éduquer tous les acteurs …
pour que les droits de l’utilisateur final soient respectés, pour qu’il se sente en confiance,“in control” et qu’il puisse toucher éventuellement une rémunération sur les contenus qui ont trouvé un vaste public.
Synthèse de veille
InnoCherche, Octobre 2016.